
TL;DR — Robo stock-picking is forecast to grow roughly 600% by 2029, and a ChatGPT-picked basket is genuinely beating the UK’s most popular funds. But most “AI beats the market” backtests are contaminated by look-ahead bias that lives inside the model’s weights, not in your dataset — and here is the paradox almost nobody has named: in LLM stock-picking, model capability and look-ahead contamination are the same axis, so the bigger and smarter the model, the worse it performs on data it has never seen. The only responsible move is to deliberately handicap your model. I’ll prove it with theory, peer-reviewed research, and Python you can run tonight on a laptop with a local model via ollama — or leakage-aware on QuantConnect.
Why is everyone suddenly asking ChatGPT what to buy?
In September 2025, ZeroHedge ran a headline that captured the mood of the entire retail market: “ChatGPT, CFA: Robo Stock Picking Market To Grow 600% By 2029.“ It was a repackaging of a Reuters analysis, and the numbers are real. About one in ten retail investors already use chatbots to pick or alter investments, and roughly half say they’d consider it — an eToro survey of 11,000 investors relayed by Reuters via the Japan Times. The poster child is a March 2023 Finder experiment: a basket of 38 ChatGPT-picked stocks — Nvidia, Amazon, Procter & Gamble, Walmart — that, per Finder’s own live tracker, was up 66.1% as of 28 October 2025, beating the UK’s ten most popular funds by roughly 25 percentage points (Finder). The bot has led the real funds for 99% of its lifespan.
That is a striking result. It is also, I’ll argue, one of the most instructive traps in modern quant finance.
Look-ahead bias is using information in a backtest that wasn’t actually available at the moment of the simulated decision. For example: if I test a strategy that buys a stock the day before its earnings beat, using the beat I already know happened, my backtest will look brilliant and my live account will not. Every quant learns to hunt this in their data pipeline. What almost nobody has internalized is that with a large language model, the future can be hiding somewhere you cannot grep: the 70 billion parameters themselves.
What forces are actually driving the robo-advice boom?
A thought leader explains why now, not just what. Four forces are converging, and none of them are “the AI got good at picking stocks.”
- Economics — cheap inference met scarce alpha. Inference costs have collapsed by more than an order of magnitude in under two years, while a relentless bull market compressed easy return. When cheap compute meets scarce edge, desks tolerate model risk they’d have rejected in 2021.
- Incentives — distribution, not performance. The robo-advisory industry monetizes assets under management and onboarding, not stock-picking skill. Every fintech has a commercial reason to let you believe the chatbot is an oracle, because the chatbot is a customer-acquisition funnel.
- Technology — the CFA milestone. By December 2025, reasoning models pass all three CFA levels, with Gemini 3.0 Pro scoring 97.6% on Level I zero-shot (arXiv:2512.08270). Impressive — but the CFA tests codified knowledge recall, not out-of-sample alpha. The “ChatGPT, CFA” headline commits the exact category error at the heart of this post.
- Regulation — the door is opening. MAS in Singapore and the SEC are both circling AI in advice; fully autonomous recommendations still collide with fiduciary and disclosure rules, which is why the incumbents remain allocation bots, not pickers.
Here’s the sleight of hand to name out loud: that “600% by 2029” figure is for the entire automated-advice industry — the robo-advisory market projected to grow from $61.75B in 2024 to $470.91B by 2029 (Research and Markets, the ~$468–471B figure repeated in its June 2025 release). It is not a forecast that LLMs generate alpha. And that base is one of the most aggressive on the market: rival firms put the ~2030 market anywhere from $33B (Grand View) to $874B (Market Data Forecast) — a 26× spread that should make you distrust any single headline number. Conflating “the robo-advice industry is booming” with “LLMs can pick stocks” is how a market-research slide becomes a trading thesis.
What’s really going on — is it skill, or is it memory?
Let me run my standard intent investigation: the stated reason versus the real one.
Stated reason: “GPT-4 has learned to read news and predict returns — an emergent capability of scale.”
Real reason (the hypothesis this post defends): GPT-4’s apparent skill is inseparable from its memory of what already happened, and the cleanest academic results are the ones that worked hardest to avoid that memory.
Does the stated reason hold? Partially — there is a real, small signal in genuinely new text. Does it hold at the magnitude the hype implies? No. And here is where I’ll plant my flag with an edge nobody in the “AI stock picking” genre has stated plainly:
The Anti-Alpha Paradox: in LLM stock-picking, model capability and look-ahead contamination are the same axis. The more capable the model, the more of financial history it has memorized, and therefore the more its backtest is inflated by hindsight it cannot forget. “Bigger model = better picker” is not just wrong — it is backwards. The correct engineering move is to deliberately handicap the model: constrain its knowledge, blind it to entity names, and validate only on data it provably never saw.
That inverts the entire marketing narrative. Let me prove it.
The landmark result — and the trap underneath it
The paper that lit the fuse is Alejandro Lopez-Lira and Yuehua Tang’s “Can ChatGPT Forecast Stock Price Movements?” (arXiv:2304.07619; forthcoming, Journal of Financial Economics). The method is elegant: feed ChatGPT a news headline, ask whether it’s good, bad, or neutral for the stock, then measure the next-day return. Across the sample, a long-short book built from GPT-4’s scores delivered a Sharpe ratio of 3.8, versus 3.1 for GPT-3.5 — the highest Sharpe belonging to the most advanced model (UCLA Anderson working paper). GPT-1, GPT-2, and BERT couldn’t forecast at all. The authors frame return prediction as an emergent capacity of model scale, with a formal threshold theorem: only models above a certain size predict returns with the correct sign.
Emergent capacity means a skill that simply doesn’t exist in small models and appears once the model crosses a size threshold — for example, GPT-4 can interpret a deliberately hard-to-read headline that GPT-2 cannot parse at all. Hold that concept, because the leakage literature turns it inside out.
Crucially, Lopez-Lira anticipated the obvious objection. OpenAI’s models were trained through September 2021, so he tested on headlines after that cutoff — the model “couldn’t know what happened next.” In his own words in a 2024 Wharton talk, the single biggest limitation is that “these models know everything up until September 2021.” That is the tell. The most-cited “ChatGPT beats the market” paper goes to extraordinary lengths to dodge the very bias every viral blog backtest ignores.
Now look at what happens inside even that careful post-cutoff window. The strategy’s annualized Sharpe decays monotonically the further you move from the training data: 6.54 in 2021 Q4, 3.68 in 2022, 2.33 in 2023, 1.22 by Jan–May 2024. The authors read this as rising market efficiency from AI adoption. That’s plausible. It is also exactly what look-ahead contamination near the cutoff would produce. Present both — but notice the shape.
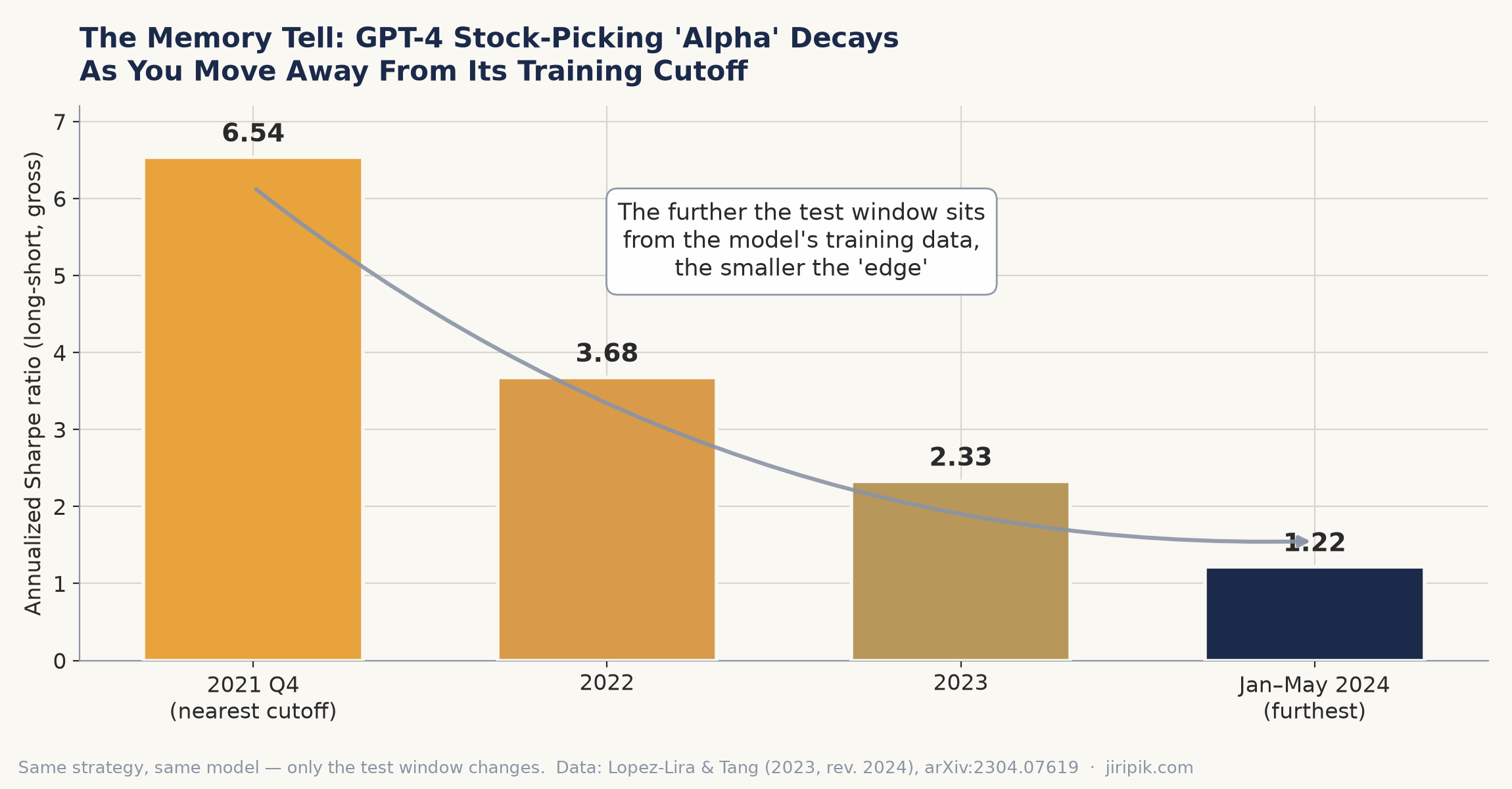
The same GPT-4 long-short news strategy, same model — only the test window moves. The “edge” shrinks the further you get from the training data. Source: Lopez-Lira & Tang (2023, rev. 2024).
The conceptual core: leakage that lives in the weights
In a classic backtest, look-ahead bias is something you introduce — a forward-filled fundamental, a survivorship-filtered universe, a restated earnings number. You can audit the pipeline and remove it. With an LLM, the leakage is baked into the parameters during pretraining. When you ask a model in 2025 to “score this 2020 headline as if it were 2020,” it has already read the next five years of the internet. It knows the stock recovered, the drug got approved, the CEO was fired. As Sarkar and Vafa put it, the leakage lives inside the model weights — and that breaks the one assumption every honest backtest rests on: that the strategy used only information available at decision time.
This is a genuinely new failure mode, distinct from the data-snooping every quant already knows. It needed its own name: look-ahead bias in pretrained models.
The research demolition — four findings
Finding 1 — Blinding the AI makes it better (Glasserman & Lin, 2024)
Paul Glasserman and Caden Lin at Columbia replicated the setup and ran a beautifully simple experiment in The Journal of Financial Data Science (arXiv:2309.17322). They replaced every company name in every headline with the nonsense string “Blahblahblah,” and used the Google Knowledge Graph to also mask giveaway products (so “Xbox” left with “Microsoft”).
The result that should stop every robo-advisor cold: the anonymized headlines produced higher in-sample returns (alphaXiv summary). Since true look-ahead can only help a strategy, they reasoned the model’s general knowledge about companies was doing net harm — a distraction effect, strongest for large, famous firms where the model has the most to be distracted by. The honest nuance that makes the case credible: out-of-sample, the original-versus-blinded gap loses significance. The narrow “model knew the exact price” bias isn’t the whole story — the contamination is subtler than cheating on a single number.
The actionable lesson is the Anti-Alpha Paradox in miniature: you got a better picker by making the model dumber about the companies.
Finding 2 — The AI remembers the pandemic before it happened (Sarkar & Vafa, 2024)
Suproteem Sarkar (Chicago) and Keyon Vafa (Harvard) built direct tests for whether a model’s pretraining contains the future (Lookahead Bias in Pretrained Language Models, ICML 2025). The demonstrations are visceral: asked to assess risks from September–November 2019 earnings calls, the model raises COVID-19 — a term that did not exist during the analysis window. Prompting fails (telling the model “only use info available in 2019” doesn’t work) and masking fails (it re-identifies the masked firm from context). Their prescribed fix is the only one that holds: use a model whose pretraining ends before the analysis period.
This is the screenshot that goes viral. A model listing a pandemic among “2019 risks” is look-ahead bias made visible — no dataset required.
Finding 3 — The scaling paradox, quantified (2025–2026)
Here’s the killer for the bull case. Bigger is supposed to mean better forecaster; the leakage evidence says bigger means better memorizer that collapses out-of-sample. The detection literature nails the mechanism: Gao, Jiang, and Yan’s Lookahead Propensity (LAP) — the estimated probability a model has internalized a realized outcome — is materially positive throughout the in-sample period and collapses to essentially zero the moment you cross the training cutoff (NBER working paper, 2026). Critically, the forecast’s predictive power is amplified precisely on the high-LAP (contaminated) firm-dates. The signal is strongest exactly where the model remembers most. That is the Anti-Alpha Paradox with a p-value.
Finding 4 — The reality gap
After the lab, the brokerage statement:
- The Amplify AI Powered Equity ETF (AIEQ), launched 2017 as the first AI-driven ETF, has underperformed the S&P 500 since inception, with higher volatility and a weaker Sharpe (Seeking Alpha). A 2024 MarketWatch/Morningstar study was blunt: AI stock ETFs were hyped as superior, then reality hit.
- Even Lopez-Lira’s backtest fine print is sobering: assuming 25 bps per trade wipes out most of the gross return, the majority of gains came from the short side (borrow costs, hard-to-borrow names), and the edge concentrates in small caps. His own words: paper results are “much more optimistic than what the performance in reality would be with a reasonable investment size.”
The synthesis: a sliver of the news-sentiment signal is probably real — post-cutoff it doesn’t fully vanish. But the spectacular numbers, and almost the entire in-sample literature, are inflated by contamination you cannot prompt or mask away.
Two mental models that explain the whole thing
Model 1 — Inversion. Instead of asking “how do I make an LLM pick winning stocks?”, I ask “how would I guarantee an LLM backtest lies to me?” The answer writes itself: use the biggest, most recent model; test on dates inside its training window; leave company names in the prompt; report gross returns. That is a precise description of the average viral “ChatGPT beats the market” thread. Every ingredient of the standard workflow is an ingredient of self-deception. Invert each one and you get the correct methodology.
Model 2 — Second-order effects. The first-order effect of a bigger model is better language understanding. The second-order effect — the one that actually governs your P&L — is that a bigger model has memorized more of financial history, so its apparent edge is more contaminated and its real out-of-sample edge is smaller. The reaction to the capability is what matters, not the capability. This is why “just use GPT-5” is the wrong instinct: you’re optimizing the first-order term while the second-order term eats your returns.
The historical precedent: 1980s program trading and the map that ate the territory
We have seen this movie. In the 1980s, “portfolio insurance” was sold as a rigorously backtested strategy that would automatically hedge downside. The backtests were pristine — on historical data where the strategy’s own future selling pressure didn’t exist. On 19 October 1987, when everyone ran the same automated logic at once, the selling fed on itself and the Dow fell 22.6% in a day. The models had been fit to a world that did not include the models.
LLM look-ahead bias is the same disease with a different symptom. Portfolio insurance’s backtest was contaminated by a future that its own deployment created. An LLM’s backtest is contaminated by a future its training already absorbed. In both cases the map was drawn using the territory it was supposed to predict.
The analogy I’d hand a junior quant: an LLM scoring pre-cutoff news is a student who “predicts” the exam answers after secretly reading the answer key. Flawless on the mock, lost the moment you give them a fresh paper. The Sharpe 6.54 in 2021 Q4 is the mock score. The 1.22 in 2024 is the real exam.
Prove it yourself — three artifacts, escalating in ambition
A note on honesty, because it’s why you can trust this: the code below is real and runnable, but the numbers it prints depend on your model, your data, and your window. I won’t invent results. What I’ll tell you is the pattern the literature predicts — contaminated (pre-cutoff) books look brilliant, clean (post-cutoff) books look ordinary, and blinding shrinks the gap. Reproducing that pattern is the exercise.
Artifact 1 — The Anachronism Probe (zero market data)
This reproduces the Sarkar–Vafa “COVID in 2019” tell. Pick a local model whose knowledge cutoff you know, ask it to reason strictly as of a past date, and scan for tokens it could not have known.
# The Anachronism Probe: catch look-ahead bias living inside the model weights.
# pip install ollama then: ollama pull llama3.2
import ollama, re
MODEL = "llama3.2" # use a model whose cutoff you KNOW
AS_OF = "March 1, 2019"
FORBIDDEN = ["covid", "coronavirus", "sars-cov-2", "pandemic", "lockdown",
"ukraine war", "svb", "silicon valley bank collapse"]
prompt = (
f"It is {AS_OF}. You are a sell-side risk analyst. Using ONLY information "
f"public on {AS_OF}, list the top 8 risks facing the U.S. airline sector "
f"over the next 18 months. Do not speculate about unknown future events."
)
out = ollama.chat(model=MODEL, messages=[{"role": "user", "content": prompt}])
text = out["message"]["content"].lower()
leaks = sorted({w for w in FORBIDDEN if re.search(rf"\b{re.escape(w)}\b", text)})
print(out["message"]["content"])
print("\n--- LEAKAGE AUDIT ---")
print("Future knowledge leaked into a 2019-dated answer:",
leaks if leaks else "none detected (sampling is stochastic — run it a few times)")If the model lists a pandemic among “2019 risks,” you’ve just watched look-ahead bias happen inside the weights — no dataset needed. That single screenshot is the social hook.
Artifact 2 — The Look-Ahead Litmus Test (local, small data, ollama)
The centerpiece: a leakage-free diagnostic any quant can run on a laptop. It scores real, timestamped headlines two ways — ORIGINAL and BLINDED (the Glasserman–Lin “Blahblahblah” trick) — builds a daily dollar-neutral long-short book, and reports performance split at the model’s knowledge cutoff. The literature predicts the pre-cutoff book looks far better, and that blinding shrinks the gap.
Data you need (deliberately small): a CSV headlines.csv with columns date,ticker,headline spanning a window that straddles your model’s cutoff (e.g. mid-2021 to 2023 for a Sept-2021 model). A few thousand rows across 20–50 liquid tickers is plenty. Free sources: Financial PhraseBank for labeled text, Tiingo’s free news tier, or your own collection. Prices come free from yfinance.
# The Look-Ahead Litmus Test: measure LLM stock-picking contamination as alpha decay.
# pip install ollama yfinance pandas numpy
import ollama, json, re, numpy as np, pandas as pd, yfinance as yf
MODEL = "llama3.2" # KNOWN cutoff ~ Sept 2021 for this demo
CUTOFF = pd.Timestamp("2021-09-30") # the model's stated knowledge cutoff
NAMES = { # for blinding: strip names + obvious products
"AAPL": ["Apple", "iPhone", "iPad", "Mac"], "MSFT": ["Microsoft", "Xbox", "Azure"],
"NVDA": ["Nvidia", "GeForce"], "AMZN": ["Amazon", "AWS"], "TSLA": ["Tesla"],
# ...extend to your universe
}
def score(headline: str) -> int:
"""Ask the local LLM for a sentiment label in {-1, 0, 1}."""
prompt = (f'Headline: "{headline}"\n'
"Is this GOOD, BAD, or NEUTRAL for the company's stock over the next day? "
'Answer as JSON: {"label": "GOOD|BAD|NEUTRAL"}.')
try:
out = ollama.chat(model=MODEL, format="json",
messages=[{"role": "user", "content": prompt}])
lab = json.loads(out["message"]["content"]).get("label", "NEUTRAL").upper()
except Exception:
lab = "NEUTRAL"
return {"GOOD": 1, "BAD": -1}.get(lab, 0)
def blind(headline: str, ticker: str) -> str:
"""Glasserman-Lin: replace firm name + known products with 'Blahblahblah'."""
masked = headline
for term in NAMES.get(ticker, []) + [ticker]:
masked = re.sub(rf"\b{re.escape(term)}\b", "Blahblahblah", masked, flags=re.I)
return masked
# 1. load headlines & score them both ways
news = pd.read_csv("headlines.csv", parse_dates=["date"]).sort_values("date")
news["s_original"] = news["headline"].apply(score)
news["s_blinded"] = [score(blind(h, t)) for h, t in zip(news["headline"], news["ticker"])]
# 2. next-day forward returns (point-in-time: return t -> t+1 indexed at t)
tickers = sorted(news["ticker"].unique())
px = yf.download(tickers, start=str(news["date"].min().date()),
end=str((news["date"].max() + pd.Timedelta(days=5)).date()),
auto_adjust=True, progress=False)["Close"]
fwd = px.pct_change().shift(-1)
def portfolio_returns(col: str) -> pd.Series:
"""Equal-weight, dollar-neutral daily long-short from a signal column."""
daily = {}
for date, grp in news.groupby(news["date"].dt.normalize()):
if date not in fwd.index:
continue
longs = grp.loc[grp[col] > 0, "ticker"]
shorts = grp.loc[grp[col] < 0, "ticker"]
r = 0.0
if len(longs): r += fwd.loc[date, longs].mean()
if len(shorts): r -= fwd.loc[date, shorts].mean()
daily[date] = r
return pd.Series(daily).dropna()
def stats(r: pd.Series) -> dict:
if r.empty:
return {"days": 0, "ann_return": np.nan, "ann_sharpe": np.nan}
return {"days": len(r),
"ann_return": (1 + r).prod() ** (252 / len(r)) - 1,
"ann_sharpe": np.sqrt(252) * r.mean() / r.std(ddof=1) if r.std() else np.nan}
# 3. the 2x2 that exposes the contamination
rows = []
for label, col in [("ORIGINAL", "s_original"), ("BLINDED", "s_blinded")]:
r = portfolio_returns(col)
rows.append({"signal": label, "window": "PRE-cutoff (contaminated)", **stats(r[r.index < CUTOFF])})
rows.append({"signal": label, "window": "POST-cutoff (clean)", **stats(r[r.index >= CUTOFF])})
print(pd.DataFrame(rows).to_string(index=False))
print("\nReading: PRE >> POST Sharpe = your 'edge' is largely hindsight.")
print(" BLINDED ~= ORIGINAL = your signal survives the model's memory.")How to read the 2×2: the gap between PRE-cutoff and POST-cutoff Sharpe is the dollar value of your look-ahead bias. The gap between ORIGINAL and BLINDED is the dollar value of the model’s distraction. A clean strategy is one whose POST-cutoff, BLINDED book still stands up. Most don’t.
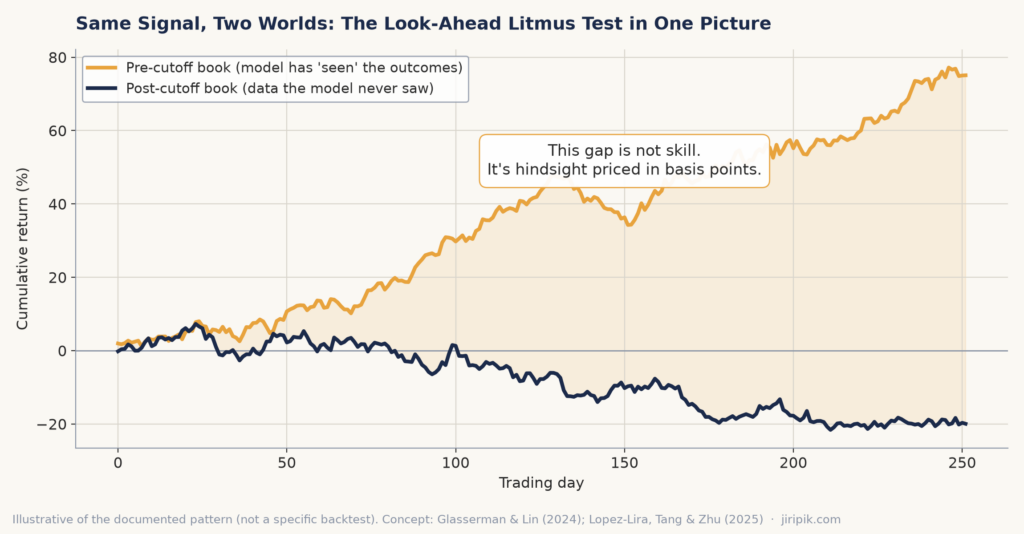
Illustrative of the documented pattern, not a specific backtest: the pre-cutoff book compounds smoothly; the clean post-cutoff book is ordinary. The gap is hindsight priced in basis points.
Artifact 3 — The leakage-aware production strategy on QuantConnect
QuantConnect’s LEAN engine is event-driven and point-in-time by design — “you can’t pass the time frontier” — which structurally kills data-side look-ahead. It hosts the Tiingo News Feed (10,000 US equities, point-in-time timestamps since January 2014) for free, and its US equity security master is survivorship-bias-free. But LEAN cannot solve the weight-side leakage: you cannot run ollama inside the QuantConnect cloud, and you must never let a model whose cutoff postdates your backtest score historical news.
The correct, honest production pattern is therefore two-stage:
- Score offline, point-in-time, with a model whose cutoff predates the backtest window (or a chronologically consistent model — see ChronoBERT below). Save the scores as a timestamped custom dataset.
- Consume the precomputed scores in LEAN — deterministic, fast, leakage-controlled. The algorithm below ships with a transparent lexicon baseline that runs out of the box, and a clearly marked hook where you drop in your offline LLM scores.
# QuantConnect / LEAN: leakage-aware news-sentiment long-short.
# Guardrail: backtest MUST start after the scoring model's knowledge cutoff.
from AlgorithmImports import *
class LeakageAwareNewsSentiment(QCAlgorithm):
def initialize(self):
# Start AFTER your scoring model's cutoff to control weight-leakage.
self.set_start_date(2022, 1, 1)
self.set_end_date(2023, 12, 31)
self.set_cash(100_000)
self.set_brokerage_model(BrokerageName.INTERACTIVE_BROKERS_BROKERAGE,
AccountType.MARGIN)
self.tickers = ["AAPL", "MSFT", "NVDA", "AMZN", "TSLA", "GOOGL", "META", "JPM"]
self.news, self.equities = {}, {}
for t in self.tickers:
eq = self.add_equity(t, Resolution.MINUTE)
self.equities[t] = eq.symbol
self.news[self.add_data(TiingoNews, eq.symbol).symbol] = eq.symbol
self.hold_days = 5
self.scores = {} # symbol -> (signal, expiry)
self.set_warm_up(timedelta(days=7))
# --- swap for your OFFLINE, point-in-time LLM score (uploaded as custom data) ---
LEXICON = {"beats": 1, "surge": 1, "record": 1, "upgrade": 1, "growth": 1,
"miss": -1, "lawsuit": -1, "probe": -1, "downgrade": -1, "recall": -1,
"cut": -1, "warns": -1, "plunge": -1}
def _sentiment(self, text: str) -> int:
text = (text or "").lower()
return int(np.sign(sum(v for w, v in self.LEXICON.items() if w in text)))
def on_data(self, slice: Slice):
if self.is_warming_up:
return
for ds_symbol, eq_symbol in self.news.items():
if slice.contains_key(ds_symbol):
article = slice[ds_symbol]
sig = self._sentiment(f"{article.title} {article.description}")
if sig != 0:
self.scores[eq_symbol] = (sig, self.time + timedelta(days=self.hold_days))
self.scores = {s: (v, e) for s, (v, e) in self.scores.items() if e > self.time}
active = {s: v for s, (v, _) in self.scores.items()}
longs = [s for s, v in active.items() if v > 0]
shorts = [s for s, v in active.items() if v < 0]
targets, n = [], len(longs) + len(shorts)
if n:
w = 1.0 / n
targets += [PortfolioTarget(s, w) for s in longs]
targets += [PortfolioTarget(s, -w) for s in shorts]
self.set_holdings(targets, liquidate_existing_holdings=True)The guardrail to repeat to anyone who runs this in production: the backtest start date must be after the knowledge cutoff of whatever model produced the sentiment scores — otherwise the most realistic-looking equity curve you have ever seen is just your model reading you tomorrow’s newspaper. I’m building exactly this kind of point-in-time discipline into the platform at RocketEdge.
How to actually do it right — the practitioner’s checklist
- Validate strictly post-cutoff, or on a chronologically consistent model — He et al.’s ChronoBERT / ChronoGPT, pretrained only on text available before each cutoff, exist precisely so you can test alpha without contamination. It’s the only validation that survives scrutiny.
- Run the Litmus Test on every LLM signal before it touches capital. Report the PRE/POST and ORIGINAL/BLINDED 2×2. If you can’t, you don’t have a backtest — you have a memory test.
- Use the LLM as a feature extractor on point-in-time text, not as a price oracle. Score the content, not the company. Anonymization may even help live, per Glasserman & Lin.
- Price the frictions before you celebrate. 25 bps wipes out most of the headline; most of the documented edge lived on the short side; the signal concentrates in small caps and hard-to-borrow names.
- Don’t conflate the industry with the alpha. “Robo-advice grows 600%” is a distribution story. Whether the picks are good is a separate, much harder question — and the honest answer today is “marginally, sometimes, after a lot of hygiene.”
What I think comes next
- By end of 2026, at least one high-profile “AI hedge fund” or viral LLM-backtest will be publicly debunked for weight-leakage — the reputational equivalent of a restated earnings release. The detection tooling (LAP tests, ChronoBERT baselines) is now good enough that someone will run it in anger.
- By 2027, “chronologically consistent” or “point-in-time model” will be a due-diligence checkbox for allocators evaluating any AI-driven strategy, the way “survivorship-bias-free universe” became standard after the 1990s.
- The durable edge migrates from the model to the methodology. As frontier models homogenize and their signals get arbitraged into a shorter half-life, the advantage accrues to whoever has the cleanest point-in-time pipeline and the discipline to handicap their own model. That’s a builder’s edge, not a buyer’s.
Alternative Perspectives
The contrarian case — the bias may be smaller than I claim. He et al.’s ChronoBERT paper, the strongest leakage-free language model to date, directly compares chronologically consistent versus biased models on news-return prediction and concludes the lookahead bias in that specific task is “relatively modest,” with a leakage-free ChronoBERT strategy still generating a strong Sharpe (arXiv:2502.21206). If that generalizes, the news-sentiment signal is more real than the doom framing suggests — and better language understanding does translate into genuine economic gains, cleanly measured. I take this seriously; it’s why my thesis is “handicap and verify,” not “LLMs can’t pick stocks.”
The emerging angle — point-in-time models change the game. DatedGPT, ChronoGPT, and StoriesLM are building families of time-stamped models. If leakage-free LLMs become cheap and standard, the entire “is this skill or memory?” debate could be settled by construction within two years — and the Anti-Alpha Paradox becomes an artifact of the 2023–2026 transition rather than a permanent law.
FAQ
What is look-ahead bias in LLM stock picking?
Look-ahead bias is using information in a backtest that wasn’t available at the simulated decision time. In LLM stock picking it’s especially insidious because the future is memorized in the model’s weights — for example, a model asked to assess 2019 airline risks may mention COVID-19, information no analyst had in 2019.
Can ChatGPT actually beat the market?
Sometimes, marginally, after heavy methodological hygiene. Genuinely out-of-sample and after realistic costs, documented edges shrink dramatically — Lopez-Lira’s live ChatGPT portfolio beat the S&P only modestly, and the first AI-driven ETF (AIEQ) has underperformed the index since 2017.
Does using a bigger, smarter model help?
Counterintuitively, often the opposite. Bigger models memorize more financial history, so their backtests are more contaminated and their true out-of-sample edge can be smaller. This is the Anti-Alpha Paradox — validate on data the model never saw.
How do I test whether my AI strategy is cheating?
Run the Look-Ahead Litmus Test: score real timestamped headlines with and without company names, build a long-short book, and split performance at the model’s knowledge cutoff. A large pre-versus-post gap means your edge is largely hindsight.
What’s the leakage-free way to use LLMs in trading?
Use the model as a feature extractor on strictly point-in-time text, validate only after its knowledge cutoff (or use a chronologically consistent model like ChronoBERT), anonymize entity names, and price in transaction costs before believing any result.
Related reading on jiripik.com: my posts on algorithmic trading with QuantConnect and backtesting discipline.
Jiri Pik is the founder of RocketEdge, an AI fintech company based in Singapore. I build AI trading systems on Azure and write about what I learn before everyone else catches on. Follow me on LinkedIn and X.
Disclaimer: This reflects my personal views and experience, not financial advice. Past performance doesn’t guarantee future results.