
The optimal database architecture depends on the structure of the data, the number of the records to be stored, their intended updates (if any), the typical queries and their frequency, and the database engine itself.
Each database engine is optimized differently and thus, for example, the best architecture for MS SQL Server would be different from the most suitable architecture for MySQL.
For a small amount of data, there is virtually no difference between a naive and the smartest architecture. The more data you store, the more pronounced the performance differences will be.
This article describes the optimal database architecture for super-fast access to historical currency market data for about 40k currency pairs in MySQL at the time of writing of this blog post.
Relational -vs- NoSQL representation of Financial Data
All timeseries financial data is fixed-structured (date, seriesId, value) and SQL databases are best suited for handling them because
- SQL Query Language – no matter how well you handle the import process, you will always encounter situations where you need to verify particular value or find values within a range or so. Without SQL language, you would spend extraordinary amount of time manually coding the queries
- Faster Processing – fixed structure of the data allows for optimization of the persisted data and unless you always require retrieval of all records, your filtering of the data (e.g. a time window – retrieve all values of the exchange rate between Jan 1 and Jan 10), allows for a quicker retrieval
- Existence of Well-Established Tools and SDKs – for all major SQL database engines, there are tons of professional tools – e.g. backup tools, reporting tools, version control tools, clients – which dramatically lower the total costs of ownership. For majority of NoSQL databases, there just a few such solutions.
AWS MySQL RDS vs AWS S3 for Historical Currency Data Persistence
AWS S3 (in a way a NoSql database) is a dramatically cheaper alternative for storing historical currency data in AWS than an AWS RDS MySQL.
The key differences are these:
| Parameter | AWS RDS MySQL | AWS S3 |
| Access Latency | A guaranteed max latency, with some data coming from in-memory caches | Access time is random, though usually very fast |
| Locking for Updates | Certain locking mechanisms for update of the data | None |
| Granularity of Access | Row data access | File access |
| Query Language | A general SQL-like query language | None |
| Costs | Thousands of USD per year | Tens of USD per year |
Thus, for high-performance data access, MySQL is the best solution.
For batch processing with very infrequent single-threaded updates, and low performance requirements, AWS S3 provides the best results.The optimal S3 file content would then be a zipped protobuffer file since the less data you transfer, the quicker it is (thus the zip compression) and since protobuffer is one of the most efficient serialization protocols available nowadays.
The text below focuses on high-performance MySQL representation of the historical currency data.
MySQL
MySQL, an open-source database management system, is the 2nd most frequently used database engine in the world:
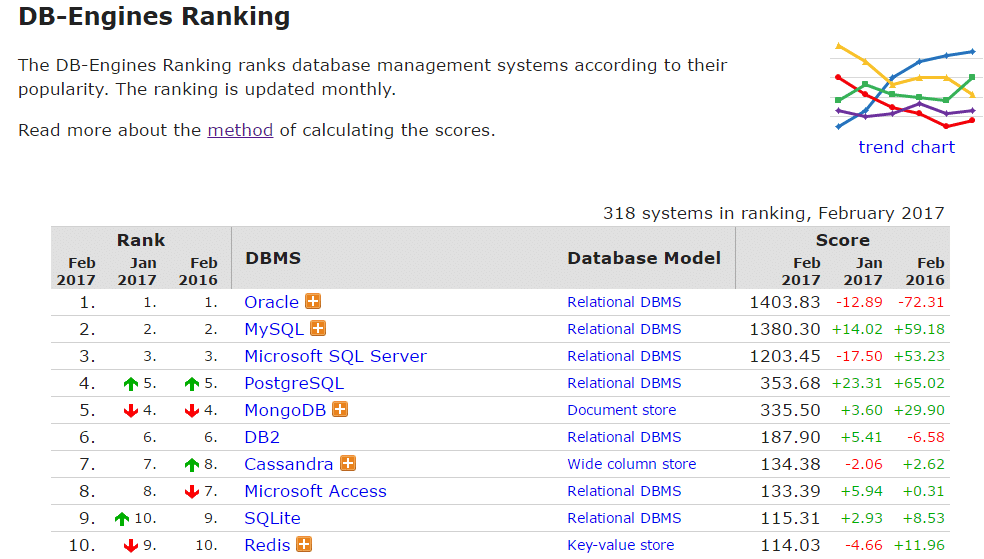
An optimized version of MySQL became AWS Aurora, or Percona Server for MySQL and also MariaDB.
The fact that MySQL has zero license costs turned the database engine into an attractive back-end for small hedge funds or financial traders.
MySQL Key Performance Facts
- Primary Key – The rows in the database tables are physically organized in the ascending order of the primary key. So, the primary key is a synonym for a clustered index. Thus, you do not need an index on the primary key.
- Table Partitioning – MySQL implementation of table partitioning is not as advanced (e.g. one cannot have a foreign key on a partitioned table) as the partitioning of any commercial database engine, like Oracle, and I do not recommend using it. Rather, partition manually like the text below suggests.
Typical Historical Currency Data Database Operations
The typical operations on a historical currency data database are:
- INSERT new rows
- UPDATE old values
- SELECT values on a given date, or max/min value over a period
Usually, DELETE operation would be very rare.
Typical Historical Currency Data Structure
The typical fields sets is
- DATE of the data
- NAME of the currency pair, e.g. USDCHF
- VALUE (double) of the currency exchange rate
- LAST_UPDATED_IN_UTC – timestamp where the value has been most recently updated
Initial Theoretically-Sound Solution
The recommended textbook architecture would be as follows – autonumber primary keys with partitioning by currency pairs:
CREATE TABLE CurrencyPairs ( CurrencyPair_ID INT AUTO_INCREMENT NOT NULL, FromCcy char(3) not null, ToCcy char(3) not null, PRIMARY KEY (CurrencyPair_ID) ); ALTER TABLE CurrencyPairs ADD INDEX IND_CurrencyPairs_FromToCcy (FromCcy, ToCcy); CREATE TABLE CurrencyPairsHistory ( CurrencyPairsHistory_ID INT AUTO_INCREMENT NOT NULL, Date Date not null, CurrencyPair_ID int not null, LowPrice decimal(24,10) null, HighPrice decimal(24,10) null, ClosePrice decimal(24,10) null, LastUpdatedInUtc timestamp null, PRIMARY KEY (CurrencyPairsHistory_ID,CurrencyPair_ID)) PARTITION BY HASH(CurrencyPair_ID); ALTER TABLE CurrencyPairsHistory ADD INDEX IND_CurrencyPairsHistory_CurrencyPair_ID (CurrencyPair_ID); ALTER TABLE CurrencyPairsHistory ADD INDEX IND_CurrencyPairsHistory_DateCurrencyPair_ID (`Date`, CurrencyPair_ID);
This architecture is not optimal because
- Poor retrieval times – it took up to a few seconds to retrieve 10 years of history for a given currency pair (i.e. in total the number of rows was 365.25 * 10)
- Huge Indices – the data for about 40k currency pairs and 10 years of history requires approx. 2 GB of table space with 8 GB huge indices
- Enormous Index Rebuilds – Each time there is an insert of a new data point, the indices have to be rebuilt making the entire MySQL unresponsive
In other words, storing all data in one big table, rather than a number of smaller tables, leads to a very few very huge files with significant times necessary for updates.
The Optimal Solution
The final solution which delivers the entire time series, or any of its subsets, in milliseconds is this:
- One values table per currency pair – For each currency pair, we have one table with the Date being the primary key -> choosing the currency pair leads to the choice of the right table (we have about 40k tables!), and Date being the primary key making searches ultra-fast
- Prepopulation of the tables with null values for every single day since Jan 1, 1999 till Jan 1, 2018 – Each table is pre-populated with blank rows with null value for every single day since Jan 1, 1999 till Jan 1, 2018 (a year from now) which eliminates the time and resources expensive index rebuilds and when a new value arrives, the corresponding row is simply updated (without triggering an index rebuild)
For top performance, modify the MySQL table_open_cache parameter:
table_open_cache=50000
Sample creation code for the currency paid CHF/USD (there would be about 40k tables of the same structure, one table per currency pair):
CREATE TABLE CHFUSD ( Date Date not null, LowPrice decimal(24,10) null, HighPrice decimal(24,10) null, ClosePrice decimal(24,10) null, LastUpdatedInUtc timestamp null, PRIMARY KEY (Date))
Recommended MySQL Clients
Opening a database connection to the above architected database in MySQL Workbench or Navicat for MySQL would take tens of minutes since those clients download the list of all database tables first.
The better MySQL clients are Toad DataPoint (commercial) or Toad for MySQL (free) which are far more powerful and provide instantaneous access to such databases.