
TL;DR: The best AI coding assistant for finance in 2026 isn’t a single tool — it’s a two-layer stack. I run GitHub Copilot for the inner loop (inline completions, Visual Studio’s .NET firepower, GitHub-native PR approvals) and Claude Opus 4.8 for the outer loop (multi-file reasoning, refactors, debugging the math). Copilot has the better hands and the better integration; Opus has the better brain. Wrap both in a model council, ground them with MCP, and design your repo so the agent can actually read it — and you flip the industry’s defining problem (66% of devs lose time to “almost-right” code) into a genuine multiplier.

Why I’m writing this
I build trading systems for a living. My day is Azure, Python, C#, QuantConnect, and the unglamorous reality that a wrong annualisation factor or a silently-deprecated pandas call doesn’t throw an exception — it just quietly loses money in production. I’ve run Copilot’s Claude tab, Claude Code, and Anthropic’s API through everything I can get them into, on real money-on-the-line code.
Most “best AI coding assistant” comparisons are written by people who’ve never had a backtest lie to them. This one isn’t. Everything below is filtered through one question: does this help me ship correct finance code faster?
And here’s the thing nobody selling you a single tool will admit: the Copilot-versus-Claude framing is a category error. They’re optimised for different loops. The real 2026 edge is workflow discipline plus the right repo architecture — the part almost nobody invests in. I’ll earn that claim below, with the latest pricing, the exact model multipliers, a model-council recipe, and the repo-design moves that have cut my agent’s wasted tokens more than any model upgrade ever did.
Disclaimer: This reflects my personal views and experience, not financial or procurement advice. Tool capabilities, pricing, and benchmarks are a June 2026 snapshot — a field that changes monthly, so verify the current numbers before you commit budget.
What’s actually broken in 2026: adoption is up, trust has collapsed
Before the tool wars, the uncomfortable context. AI coding adoption has gone vertical while trust has cratered.
| Metric | 2026 reality | Source |
|---|---|---|
| Developers using or planning AI tools | 84% | Stack Overflow 2025 |
| AI-generated or assisted code committed | 42% (up from 6% in 2023) | SonarSource 2026 |
| Trust in AI accuracy | 29% (down from ~40%) | Stack Overflow blog |
| Devs who spend more time fixing “almost-right” code than they save | 66% | SonarSource 2026 |
The headline frustration — cited by 66% of developers — is “AI solutions that are almost right, but not quite.” Experienced developers show the highest distrust. That’s not Luddism; it’s pattern recognition.
Here’s the reframe. In most domains, almost-right code is a productivity tax. In finance, it’s a latent loss. Your verification burden isn’t optional overhead — it’s the actual job. Everything I recommend is built around shrinking the almost-right surface area, and most of that lever isn’t the model at all. It’s how you wire up the workflow and the repo.
What is the two-loop mental model for AI coding?
Stop treating this as a single-winner contest. I run my tools across three loops, and the tool changes with the loop.
| Loop | Tool I reach for | What I’m doing |
|---|---|---|
| Inner loop (seconds) | Copilot inline completions / Next Edit Suggestions | Writing the next line, a LINQ chain, a pandas transform. Free, unlimited, instant. |
| Mid loop (minutes) | Copilot Edit/Agent or Claude Code | Implement a feature, fix a multi-file bug, write tests |
| Outer loop (hours) | Claude Opus 4.8 (Plan mode → agent) | Refactor the risk engine, migrate .NET Framework to .NET 8, debug the numerical logic |

This is exactly how I run it. Copilot for the keystroke-level flow, Opus for the reasoning. They don’t compete for the same keystroke — and a viral comparison thread that tested all three landed on the same conclusion: “the choice of model mattered less than the overall workflow.”
Where does Copilot win? The hands, the IDE, and the GitHub glue
Copilot’s moat is native, low-friction integration everywhere you already work — and a few things Claude Code structurally cannot do.
- Inline completions and Next Edit Suggestions. Industry-best tab completion that predicts your next edit, not just the current line. It stays free and unbilled even under the new usage model (GitHub). Claude Code has no inline-completion equivalent — none. A freeCodeCamp experiment that swapped Copilot for Claude Code on daily autocomplete called it “the worst of both worlds.”
- Visual Studio 2026 is a different league for .NET and C++. Full awareness of solution structure, project references, NuGet, and MSBuild; a multi-file diff summary with per-chunk accept/undo; a real-time context-window donut; in-IDE plan mode; and for C++, a
@BuildPerfCppagent that auto-collects MSVC ETL traces to fix build bottlenecks (Microsoft). There is nothing like this in a terminal tool. - GitHub-native PR workflow. This is underrated and it’s the reason Copilot sits in my stack permanently. Copilot turns an issue into a PR, writes the PR summary, runs agentic code review on GitHub Actions, and its cloud agent opens draft PRs you can keep working alongside. Claude Code does not open or approve GitHub PRs for you — you bolt that on yourself. If your team lives in GitHub, Copilot is the only tool that closes the issue → PR → review → merge loop natively.
- It’s becoming required infrastructure. Microsoft’s new always-on agent, Microsoft Scout, uses your GitHub Copilot Business or Enterprise license for token billing — sign-in literally fails without one (Microsoft Learn). If you’re a Microsoft shop, a Copilot seat is no longer just a coding tool; it’s the entry ticket to the broader agent platform.
- PowerShell and CLI integration. The Copilot CLI (
npm install -g @github/copilot) drops the agent straight into Windows Terminal, and Oh My Posh ships a live Copilot quota segment so you can watch your credit burn in your PowerShell prompt (Microsoft for Developers). For a Windows-heavy quant stack, that native PowerShell loop matters. - A 20+ model picker — Claude, GPT-5.x, Gemini, Microsoft MAI in one dropdown. This is also exactly what makes Copilot the best home for a model council. More on that below.
Where does Claude Opus win? The brain and the math
Claude Code is agent-first by architecture, built for tasks that span 20 to 50+ files.
- CLAUDE.md persistent memory. A project-root file read at the start of every session. Encode your standards, “never touch the execution layer without a passing test,” preferred libraries. This single file kills most context-drift complaints.
- Hooks — deterministic scripts that always fire on lifecycle events (post-edit lint, refuse to end the session until tests are green). Enforce critical rules via hooks, not prose, which drifts.
- Plan mode — read-only exploration that produces an editable plan before a single line is written. The single best discipline for finance code.
- Checkpoints and
/rewind— automatic snapshot before every edit; roll back cleanly. Makes ambitious refactors safe. - Subagents and Dynamic Workflows — Opus 4.8 can plan a job and run hundreds of parallel subagents in one session, verifying outputs before reporting back (Anthropic). This is how Jarred Sumner ported Bun’s 750k lines from Zig to Rust at a 99.8% test pass rate, and how Rakuten’s engineer had Claude refactor a 12.5-million-line library in seven autonomous hours.
- Bigger, better-used context. Opus 4.8 supports a 1M-token window with the best effective range of the frontier models. Effective beats advertised — and that gap matters once your codebase is real.
Why Opus specifically, for finance
This is the part I hold strongest conviction on: for finance code, Opus 4.8 is the model. Not because it’s fashionable — because the failure modes it avoids are the exact ones that cost money.
| Benchmark | Claude Opus | Best competitor | Why it matters |
|---|---|---|---|
| SWE-bench Verified | 88.6% (Opus 4.8) | GPT-5.3 Codex ~85% | Fixing real bugs in real code (BenchLM) |
| SWE-bench Pro (hard, decontaminated) | 69.2% (Opus 4.8) | GPT-5.5 58.6% | Polyglot, closer to real trading stacks (Vellum) |
| Finance Agent (Vals AI) | 64.4% (Opus 4.7, #1) | GPT-5.5 51.8% | Multi-step analysis on SEC filings (llm-stats) |
The benchmark numbers are nice. The reliability gain is the real story: Anthropic reports Opus 4.8 is ~4x less likely than its predecessor to let flaws in its own code pass unremarked (Anthropic). For a risk model, a model that “correctly reports when data is missing instead of providing plausible-but-incorrect fallbacks” is worth more than any Elo point.
The honest counterweight you won’t get from a fan post: no model is reliable on the hardest finance reasoning yet. On Vals AI’s Finance Agent v2, the hardest categories (Financial Modeling, Precedents) top out at ~23%, and every frontier model collapses there — Opus, GPT, and Gemini alike. On v2 overall, Opus 4.8 (53.9%) even sits behind Gemini 3.5 Flash (57.9%). “AI replaced the quant” is hype. Opus is the best general-purpose engine for finance code — multi-step financial-model synthesis still needs a human.
How much does Claude Opus actually cost inside Copilot — and which Opus do you even get?
Here’s a nuance that trips up a lot of finance devs, and your instinct that “Copilot Opus is limited” is correct on two axes: cost and capability.
Cost. Copilot resells Opus, but at a steep request multiplier. When Opus 4.8 went GA in Copilot on 28 May 2026, it launched with a 15x premium-request multiplier (GitHub Changelog). That’s the trap most people miss: a single model can quietly count as many requests.
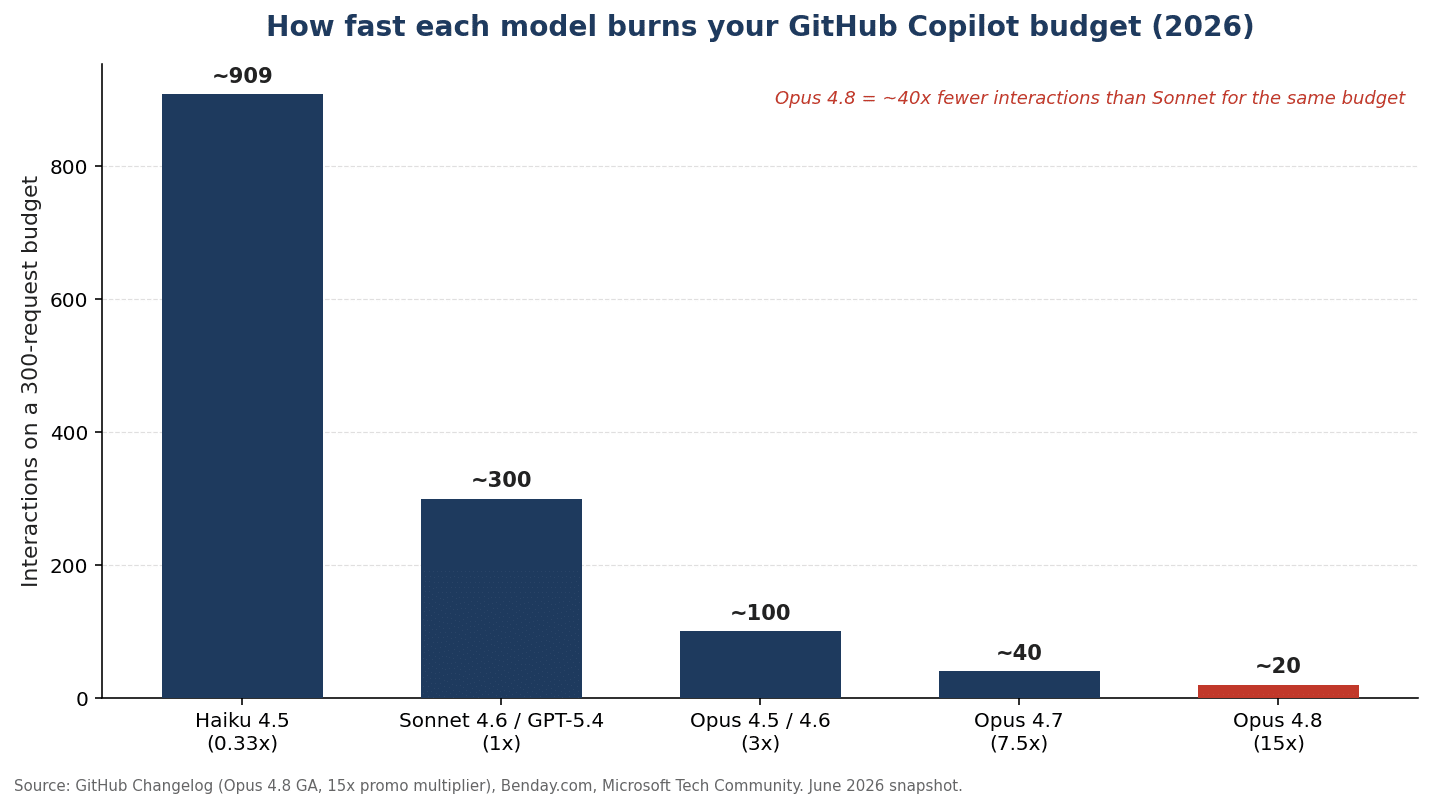
As of 1 June 2026, Copilot moved all plans to usage-based GitHub AI Credits (1 credit = $0.01, billed on tokens × per-model rate). Inline completions stay free, but agentic Opus work is now metered — and people have burned 8% of a monthly allotment in two hours (GitHub community).
Capability and availability. Copilot exposes a thinner slice of Opus than Anthropic does:
- Opus is gated to Pro+ ($39/mo), Business, and Enterprise. It was pulled from $10 Copilot Pro entirely — Pro now gives you zero Opus access (GitHub). Enterprise/Business admins must explicitly enable the Opus 4.8 policy.
- Copilot caps the input context. GitHub clamps Claude’s window to ~192K tokens (up from 128K) and reserves ~30% for output, versus Claude Code’s 200K-to-1M with only ~16.5% reserved (GitHub community). So Copilot Opus has less room to think than the same model in Claude Code.
- No reasoning-effort dial. Anthropic’s native Opus 4.8 exposes an
effortcontrol (low/medium/high/xhigh) to trade compute for depth; Copilot’s picker surfaces only the version, not the dial. For hard finance reasoning,xhighis exactly what you want — and you can’t reach it through Copilot. - And the kicker: Anthropic’s $20 Pro plan gives full Opus 4.8 with the effort dial — half the price of the Copilot tier you need for any Opus.
Practical takeaway: if Opus is your finance workhorse — and it should be — get the model from the source for depth and price, and pay Copilot for the tooling around the model (inline flow, Visual Studio, GitHub PR glue, Scout access), not for model access.
A sharp question: if the model is increasingly a commodity in a dropdown, but the effort dial, the grounding layer, and the repo architecture are where correctness lives — are you optimising the right variable when you obsess over which Opus version is in the picker?
Which model is best for UI and CLI code?
You asked the right question, and the answer surprised me when I dug into the 2026 data.
- UI / frontend code → Claude Code (Opus) wins. Multiple head-to-head comparisons attribute this to Claude’s richer MCP and skill ecosystem around frontend tooling; it “wins consistently on UI work” and on Figma-to-code cloning (Firecrawl). Trading dashboards, WPF terminals, React risk consoles — Opus produces cleaner, more idiomatic output (a 67% win rate in blind code-quality tests, per NxCode).
- CLI / terminal-native / DevOps → Codex (GPT-5.x-Codex) wins. Codex CLI leads Terminal-Bench 2.0 at 77.3% versus Claude Code’s 65.4% — a 12-point gap on the exact workflow both target — and uses roughly 4x fewer tokens for equivalent tasks (NxCode). GPT-5-Codex was purpose-built for the CLI, IDE extension, and cloud agent (OpenAI). For shell scripting, system administration, and CI/CD glue, Codex is the efficient, autonomous pick — and it’s in Copilot’s picker (
GPT-5.3-Codex).
So the refined rule for a quant stack: Opus for the trading UI and the math, Codex for the DevOps and CLI tooling, Copilot’s inline engine for the keystrokes. Same picker, different jobs.
How do you build a model council in Copilot? (The highest-leverage trick I’ve added this year)
This is the move that earns its own section, and Copilot’s multi-model picker makes it nearly free.
When a model reviews its own code, it’s proofreading its own essay — it sees what it meant, not what it wrote. When a different model reviews it, the blind spots light up. The practitioner consensus is striking: Claude tends to over-engineer; Codex tends to take shortcuts — so they fail in complementary ways and each reliably catches the other’s flaws (r/ClaudeCode).
This isn’t fringe. Andrej Karpathy open-sourced LLM Council; Mozilla shipped a Star Chamber skill for multi-LLM consensus review; and Perplexity launched Model Council on 5 February 2026, running a query across frontier models in parallel and synthesising the result (Mozilla.ai). The pattern has a name now because it works.
My pragmatic council recipe inside Copilot — no extra tooling:
- Build with Opus 4.8. Generate the change in your preferred surface.
- Switch the model picker to GPT-5.5 or GPT-5.3-Codex and prompt it cold: “Review this diff against the spec. Flag correctness, edge cases, and anything that looks like a shortcut. You have no knowledge of the prior author’s reasoning.” The fresh context is the whole point.
- Switch to Gemini 3.1 Pro for a third independent pass on anything that moves money.
- Feed the reviews back to Opus framed as a challenge: “As the CTO, evaluate these review comments. Disagree where warranted, but justify your stance.”
- Classify by agreement. When two or three models independently flag the same line, that’s a real issue — address it first. A single-model flag is a maybe. This is exactly the Star Chamber’s consensus/majority/individual triage.
The enterprise data backs the ROI: a second model dropped combined hallucination on high-stakes figures to 2.6%, because “discrepancies between model outputs on specific numbers reliably flag errors” (National Law Review). For a number that moves money, a second and third opinion costs five minutes.
# Minimal council loop you can run today in Copilot CLI or chat:
# 1. Build: @agent implement the change with Opus 4.8
# 2. Review: /model gpt-5.5 -> "Review this diff cold. Find shortcuts + edge cases."
# 3. Review: /model gemini-3.1-pro -> same prompt, independent pass
# 4. Reconcile:/model opus-4.8 -> "As CTO, evaluate these reviews. Disagree with reasons."How should you architect the repo so the agent actually performs?
Here’s the part I care about most, because it’s where I’ve found the biggest, cheapest wins — and it has nothing to do with which model is in the dropdown. The model is increasingly commoditised. Your repo architecture and your prompt discipline are not. These are the moves that moved the needle for me.
1. Kill the monolith. More files in one repo means more context to burn.
Every file the agent has to load to understand a change is context it can’t spend on reasoning. A monolithic repo forces the model to hold the whole world in its head — and you’ve already seen that Copilot clamps Claude to ~192K tokens with a third reserved for output. Decompose into microservices or cleanly separated modules. Give the agent a small, self-contained surface — the market-data service, the risk-overlay service, the execution adapter — and its effective reasoning per token goes up sharply. This is the same principle as portfolio diversification: you isolate the blast radius and you reason about one bounded thing at a time. Smaller context, sharper agent, lower bill.
2. Put a docs/ folder in every solution. This is the single biggest speed-up I’ve found.
Stop making the agent re-derive your architecture every session. In each repo, maintain a docs/ folder with Markdown that the agent reads before it touches code:
architecture.md— the components, the data flow, the boundaries, with Mermaid diagrams of the system inline (agents parse Mermaid natively).goals.md— what this service is for, its non-goals, and its invariants (“never look ahead in time”, “all P&L in base currency”).decisions.md— an append-only log of what’s been tried. For backtesting strategies especially, record what was tried and failed and why. When the agent knows you already tested a 20-day lookback and it introduced survivorship bias, it doesn’t waste a session — and your credits — rediscovering the same dead end. This one habit has dramatically sped up my strategy iteration.
# docs/decisions.md — append-only; the agent reads this first
## 2026-05-12 Mean-reversion lookback
- Tried: 20-day z-score entry. REJECTED.
- Why: survivorship bias from the delisted-names filter; Sharpe collapsed out-of-sample.
- Don't retry without point-in-time universe.
## 2026-05-19 Vol targeting
- Tried: 10% annualised vol target, daily rebal. KEPT.
- Why: cut max drawdown 38% -> 22% with ~flat return. Annualisation factor = 252, verified.Reference the folder from CLAUDE.md or .github/copilot-instructions.md so it’s loaded automatically. You’re trading a few hundred tokens of docs for thousands of tokens of rediscovery. The math always wins.
3. Minimise skills. Many of them are already built into Claude — adding them is redundant overhead.
The instinct to bolt on every skill and MCP server you can find is a trap. Connecting four MCP servers can eat one-third of your context window — ~60,000 tokens — before you write a line, and flooding the model with 100+ tools degrades its ability to pick the right one (r/ClaudeCode). A lot of skills duplicate capabilities Opus already has natively. MCP is a scalpel, not a buffet. My standing rule: run only the grounding the model genuinely lacks — Perplexity MCP (live market/regulatory facts past the cutoff) and Context7 MCP (version-accurate library docs that kill phantom pandas/QuantLib APIs) — plus your one essential integration (GitHub). Prune everything else. Specify objectives, not procedures, and let the model find the path. It’s better at that than your scaffolding is.
# The only two grounding servers I keep permanently:
claude mcp add perplexity --env PERPLEXITY_API_KEY="..." -- npx -y @perplexity-ai/mcp-server
claude mcp add --transport http --header "CONTEXT7_API_KEY: ..." context7 https://mcp.context7.com/mcpThe hallucination research is decisive on why this combination matters: for code-reference errors, “the mitigation is grounding via MCP, not prompting” — and Opus 4.7 with extended thinking plus retrieval grounding plus human review brings hallucination from 19% to under 1% (Digital Applied).
4. Verify against a known benchmark, not the compiler.
In finance, “it compiles” and “it runs clean” prove nothing. Re-run a strategy against a result you already trust — a published Sharpe, a hand-checked P&L. Explicitly ask the model to audit for the four classic quant shortcuts: lookahead bias, wrong annualisation factor, survivorship bias, and silent NaN-fills. These are the failures that run perfectly and lose money quietly.
The language breakdown: .NET/C#, C++, Python
| Language | Best assistant | Why | Hard rule |
|---|---|---|---|
| .NET / C# | Copilot (Visual Studio) | Solution-aware, type-aware, native VS tooling, GitHub PR glue | Hand whole-solution refactors to Opus |
| C++ | Claude Opus | Context size + self-correction for templates and undefined behaviour | A senior engineer owns latency-critical paths |
| Python (quant) | Claude Opus | Numerical reasoning beats autocomplete; big-context debugging | Validate math against known benchmarks, not the interpreter |
For C++ the rule is absolute: “it compiles” is the start of review, never the end. Data races, dangling pointers, and signed overflow all pass the compiler and detonate in production. AI scaffolds; a human owns anything lock-free or microsecond-critical.
What I think comes next
- By Q4 2026, the model picker is a commodity and the differentiator is your grounding-and-verification layer. The teams that win won’t be the ones with the newest Opus — they’ll be the ones whose repos are designed for agents and whose model councils are automated. I’m building exactly this discipline into the platform at RocketEdge.
docs/-as-context becomes a standard, then a spec. Within 12 months I expect “agent-readable architecture docs” to be a first-class part of repo scaffolding tools, the wayREADMEandLICENSEare today.- Usage-based billing forces architecture discipline. Now that every Opus token is metered, the monolith-versus-microservices decision is a cost decision, not just an engineering one. The cleanest repos will literally be the cheapest to run.
Alternative perspectives
The contrarian view: maybe you should standardise on one tool, not two. Context-switching between Copilot and Claude has a real cognitive cost, and a team that masters Claude Code’s hooks/subagents/Plan-mode deeply might out-ship a team that dabbles in both. There’s a credible argument that depth in one agentic tool beats breadth across two. My counter: the inner-loop completion gap is too large to give up, and the GitHub PR glue is too valuable in a GitHub shop — but if your team isn’t on GitHub and lives in the terminal, single-tool Claude Code is a defensible call.
The emerging angle: managed agents may eat the “two-tool stack” entirely. Microsoft Scout and Codex Cloud point toward always-on, fully-managed agents where you stop choosing models at all — the platform routes for you. If that lands, the skill that matters won’t be model selection; it’ll be writing specs and architecture docs clean enough that an opaque router can’t get them wrong. Which, conveniently, is exactly the discipline I’m telling you to build now.
FAQ
Which AI coding assistant is best for finance in 2026?
There’s no single winner — it’s a stack. GitHub Copilot for the inner loop (inline completions, Visual Studio, GitHub PR workflows) and Claude Opus 4.8 for the outer loop (multi-file reasoning, refactors, debugging the math). Opus is the strongest general-purpose model for hard finance code.
Is Claude Opus better than GitHub Copilot?
They’re not competitors. Opus has the better reasoning brain; Copilot has the better hands and integration. Copilot resells Opus, but exposes a thinner slice — gated to Pro+ and above, with a capped context window and no reasoning-effort dial.
How much does Claude Opus 4.8 cost in GitHub Copilot?
Opus 4.8 launched in Copilot with a 15x premium-request multiplier and is now billed via usage-based GitHub AI Credits. It’s unavailable on $10 Copilot Pro — you need Pro+ ($39/mo), Business, or Enterprise. Anthropic’s own $20 Pro plan gives full Opus 4.8 with the effort dial.
What’s the best AI model for UI and CLI code?
Claude Code (Opus) wins UI and frontend work; Codex CLI (GPT-5.x-Codex) wins terminal-native, DevOps, and scripting tasks, leading Terminal-Bench 2.0 and using ~4x fewer tokens.
How do I stop my AI coding assistant from hallucinating finance APIs?
Ground it. Add Context7 MCP for version-accurate library docs and Perplexity MCP for live market and regulatory facts, keep a docs/ folder of your architecture and tried-and-failed decisions, and run a model council so a second model catches what the first missed.
If this was useful, follow me on LinkedIn and X where I write about AI, cloud, and quant trading 6–18 months before it hits the mainstream. If you’re rebuilding your own agent workflow around repo architecture and model councils, that’s exactly what I’m building into the platform at RocketEdge. How are you architecting your repos for agents — monolith or microservices? I’m curious.
Jiri Pik is the founder of RocketEdge, an AI fintech company based in Singapore. He builds AI trading systems in the cloud and writes about what he learns before everyone else catches on.
Disclaimer: This reflects my personal views and experience, not financial advice. Past performance doesn’t guarantee future results. Pricing, model versions, and benchmarks are a June 2026 snapshot and change monthly — verify current numbers before committing budget.